Navigating the Complexities of Data: Understanding MapReduce and its Impact
Related Articles: Navigating the Complexities of Data: Understanding MapReduce and its Impact
Introduction
With enthusiasm, let’s navigate through the intriguing topic related to Navigating the Complexities of Data: Understanding MapReduce and its Impact. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
Navigating the Complexities of Data: Understanding MapReduce and its Impact
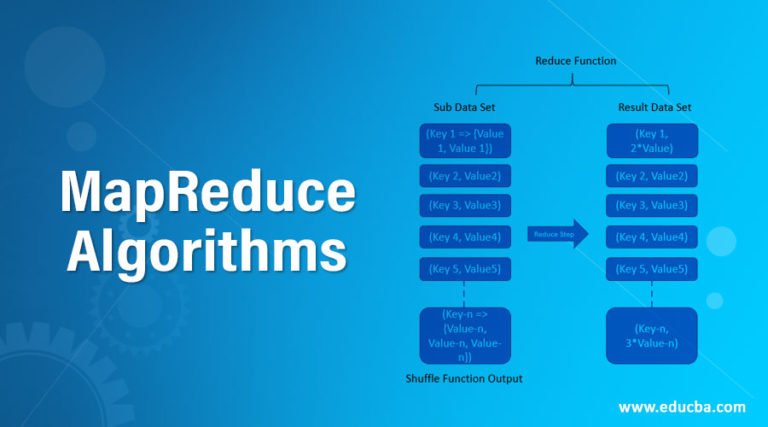
In the contemporary landscape of data analysis, the ability to process and extract insights from massive datasets is paramount. This challenge is addressed by a distributed computing framework known as MapReduce. This framework provides a powerful and scalable solution for handling the complexities of big data, enabling efficient analysis and processing across vast amounts of information.
The Essence of MapReduce:
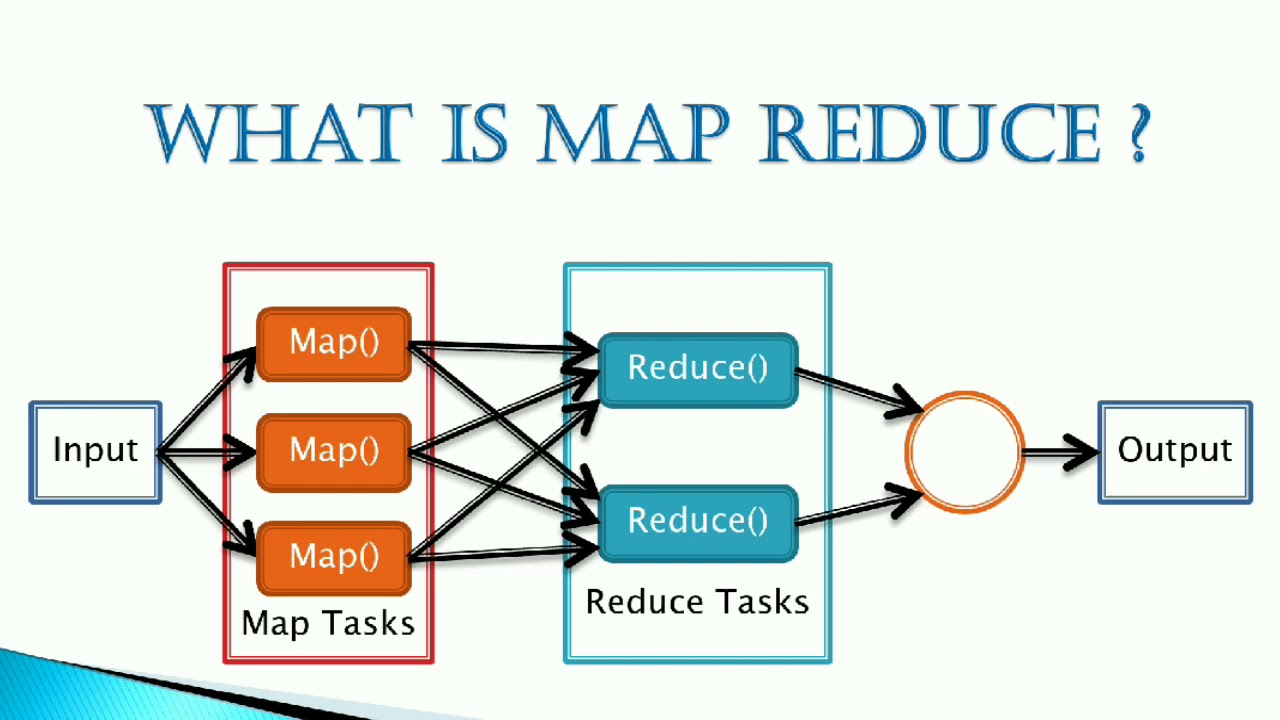
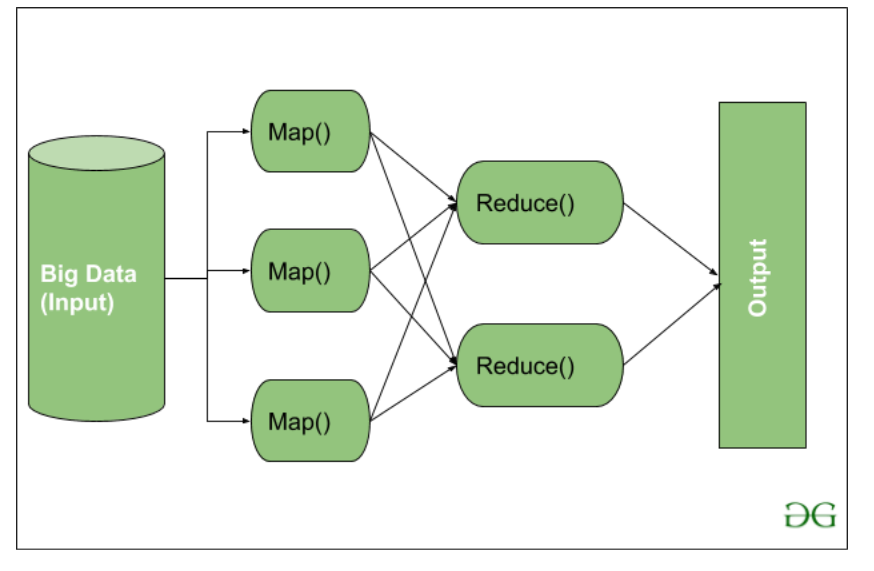
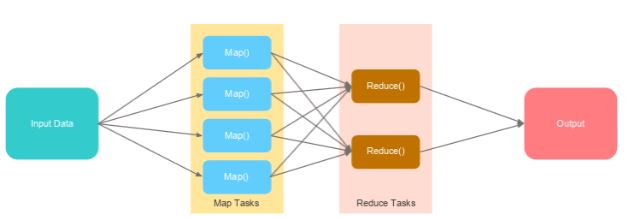
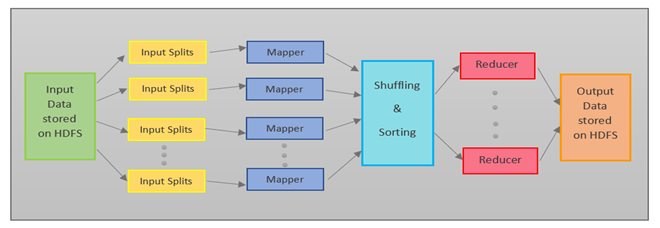
MapReduce, as its name suggests, operates in two distinct phases:
-
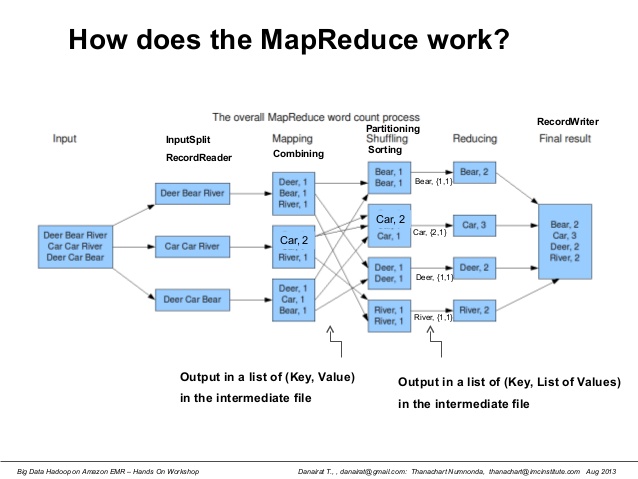
Map: The initial phase involves distributing the input data across multiple nodes within a cluster. Each node processes a portion of the data, applying a user-defined "map" function. This function transforms the raw data into key-value pairs, where the key represents a specific category and the value holds associated information.
-
Reduce: Once the map phase is complete, the framework gathers the generated key-value pairs and sorts them by key. The sorted data is then distributed across the nodes again. Each node processes the data for a particular key, applying a user-defined "reduce" function. This function aggregates the values associated with each key, performing operations such as summation, counting, or other desired calculations.
Benefits of MapReduce:
The inherent advantages of MapReduce make it a powerful tool for handling big data:
-
Scalability: MapReduce excels in handling massive datasets. The framework can easily scale by adding more nodes to the cluster, distributing the workload and enhancing processing capacity. This allows for efficient analysis of datasets that would be impractical or impossible to process on a single machine.
-
Fault Tolerance: MapReduce is designed to be resilient to failures. If a node fails during processing, the framework automatically redistributes the workload to other nodes, ensuring uninterrupted operation and data integrity. This inherent fault tolerance makes MapReduce highly reliable for critical data processing tasks.
-
Parallelism: MapReduce leverages parallelism by executing the map and reduce functions concurrently on multiple nodes. This significantly speeds up processing time, enabling faster analysis and quicker insights.
-
Simplicity: The framework’s design promotes simplicity and ease of use. Developers can focus on defining the map and reduce functions, while the underlying infrastructure handles the complexities of data distribution, task scheduling, and error handling.
Applications of MapReduce:
MapReduce finds extensive applications across various domains, including:
- Data Analytics: Analyzing massive datasets for insights, trends, and patterns.
- Search Engine Indexing: Processing and indexing vast amounts of web content for efficient search results.
- Social Media Analysis: Analyzing user interactions, trends, and sentiment in social media platforms.
- Scientific Research: Processing and analyzing large datasets in fields like genomics, astronomy, and climate science.
- E-commerce: Analyzing customer behavior, product recommendations, and fraud detection.
Beyond MapReduce: Evolution and Alternatives
While MapReduce has been a cornerstone of big data processing, advancements in technology have led to the emergence of alternative frameworks and approaches:
- Hadoop: A popular open-source framework that provides a platform for running MapReduce jobs. It offers a comprehensive ecosystem for managing and processing large datasets.
- Spark: A faster and more versatile framework that offers in-memory processing capabilities, enhancing performance for iterative algorithms and real-time applications.
- Apache Flink: A framework designed for stream processing, enabling real-time analysis of continuously arriving data.
- Cloud-based Services: Cloud providers offer managed services for big data processing, simplifying deployment and management while providing scalability and resilience.
FAQs about MapReduce:
-
Q: What are the limitations of MapReduce?
A: While MapReduce is powerful, it has limitations. It can be less efficient for iterative algorithms and tasks requiring complex data structures. Additionally, its batch processing nature may not be suitable for real-time applications.
-
Q: How does MapReduce handle data security?
A: MapReduce inherently does not provide data encryption. However, various security measures can be implemented at different levels, including data encryption during storage and transmission, access control mechanisms, and secure communication protocols.
-
Q: What are the key considerations for choosing a MapReduce framework?
A: Factors like the specific data processing requirements, performance expectations, scalability needs, and available infrastructure should be considered when selecting a MapReduce framework.
Tips for Implementing MapReduce:
- Optimize Data Structures: Use efficient data structures and algorithms to optimize map and reduce functions.
- Partition Data Strategically: Divide the data into smaller partitions to distribute the workload effectively.
- Leverage Combiners: Use combiners to perform intermediate aggregation within the map phase, reducing data volume and improving performance.
- Consider Data Locality: Store data on nodes where it is likely to be processed, minimizing network transfer time.
- Monitor and Tune Performance: Regularly monitor the performance of MapReduce jobs and make adjustments to optimize efficiency.
Conclusion:
MapReduce has revolutionized the way we handle and analyze big data. Its ability to distribute processing across multiple nodes, ensuring scalability, fault tolerance, and parallelism, has made it a valuable tool for various applications. While newer frameworks and approaches continue to emerge, MapReduce remains a foundational technology for data processing, providing a robust and reliable solution for extracting valuable insights from massive datasets. Understanding the principles and benefits of MapReduce is crucial for navigating the ever-evolving landscape of big data analysis.



Closure
Thus, we hope this article has provided valuable insights into Navigating the Complexities of Data: Understanding MapReduce and its Impact. We hope you find this article informative and beneficial. See you in our next article!